


Robots are amazing things, but outside of their specific domains they are incredibly limited. So flexibility — not physical, but mental — is a constant area of research. A trio of new robotic setups demonstrate ways they can evolve to accommodate novel situations: using both “hands,” getting up after a fall, and understanding visual instructions they’ve never seen before.
The robots, all developed independently, are gathered together today in a special issue of the journal Science Robotics dedicated to learning. Each shows an interesting new way in which robots can improve their interactions with the real world.
On the other hand…

First there is the question of using the right tool for a job. As humans with multi-purpose grippers on the ends of our arms, we’re pretty experienced with this. We understand from a lifetime of touching stuff that we need to use this grip to pick this up, we need to use tools for that, this will be light, that heavy, and so on.
Robots, of course, have no inherent knowledge of this, which can make things difficult; it may not understand that it can’t pick up something of a given size, shape, or texture. A new system from Berkeley roboticists acts as a rudimentary decision-making process, classifying objects as able to be grabbed either by an ordinary pincer grip or with a suction cup grip.
A robot, wielding both simultaneously, decides on the fly (using depth-based imagery) what items to grab and with which tool; the result is extremely high reliability even on piles of objects it’s never seen before.
It’s done with a neural network that consumed millions of data points on items, arrangements, and attempts to grab them. If you attempted to pick up a teddy bear with a suction cup and it didn’t work the first ten thousand times, would you keep on trying? This system learned to make that kind of determination, and as you can imagine such a thing is potentially very important for tasks like warehouse picking for which robots are being groomed.
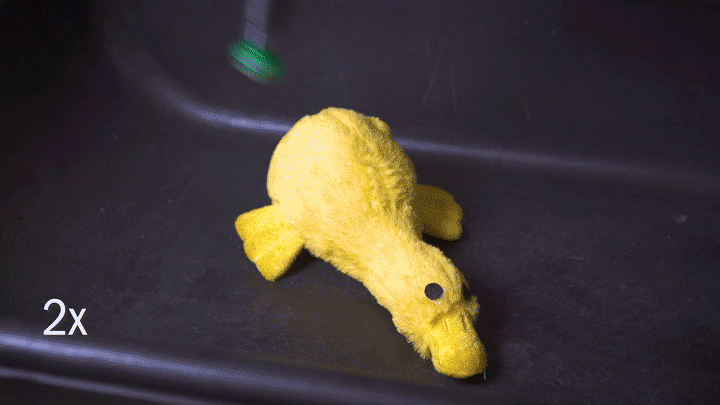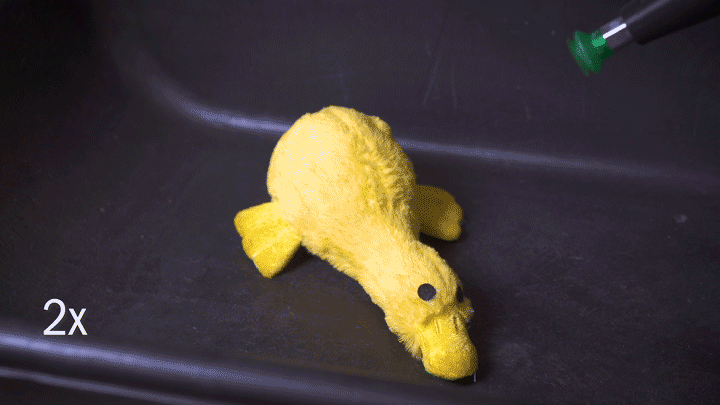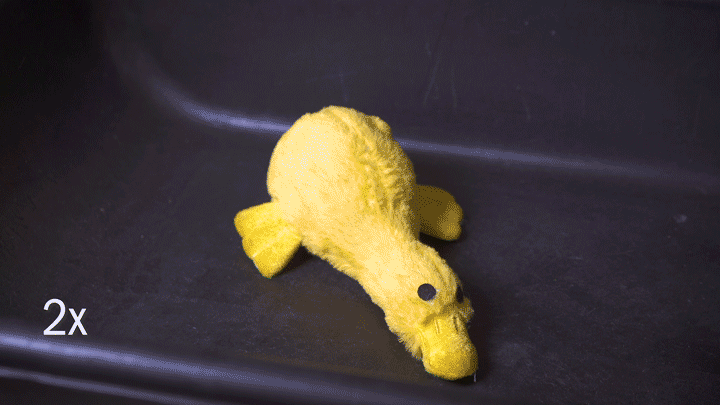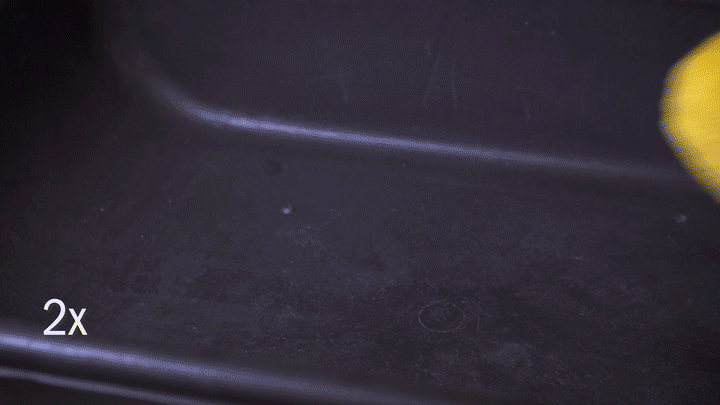
Interestingly, because of the “black box” nature of complex neural networks, it’s difficult to tell what exactly Dex-Net 4.0 is actually basing its choices on, although there are some obvious preferences, explained Berkeley’s Ken Goldberg in an email.
“We can try to infer some intuition but the two networks are inscrutable in that we can’t extract understandable ‘policies,’ ” he wrote. “We empirically find that smooth planar surfaces away from edges generally score well on the suction model and pairs of antipodal points generally score well for the gripper.”
Now that reliability and versatility are high, the next step is speed; Goldberg said that the team is “working on an exciting new approach” to reduce computation time for the network, to be documented, no doubt, in a future paper.
ANYmal’s new tricks

Quadrupedal robots are already flexible in that they can handle all kinds of terrain confidently, even recovering from slips (and of course cruel kicks). But when they fall, they fall hard. And generally speaking they don’t get up.
The way these robots have their legs configured makes it difficult to do things in anything other than an upright position. But ANYmal, a robot developed by ETH Zurich (and which you may recall from its little trip to the sewer recently), has a more versatile setup that gives its legs extra degrees of freedom.
What could you do with that extra movement? All kinds of things. But it’s incredibly difficult to figure out the exact best way for the robot to move in order to maximize speed or stability. So why not use a simulation to test thousands of ANYmals trying different things at once, and use the results from that in the real world?

This simulation-based learning doesn’t always work, because it isn’t possible right now to accurately simulate all the physics involved. But it can produce extremely novel behaviors or streamline ones humans thought were already optimal.
At any rate that’s what the researchers did here, and not only did they arrive at a faster trot for the bot (above), but taught it an amazing new trick: getting up from a fall. Any fall. Watch this:
It’s extraordinary that the robot has come up with essentially a single technique to get on its feet from nearly any likely fall position, as long as it has room and the use of all its legs. Remember, people didn’t design this — the simulation and evolutionary algorithms came up with it by trying thousands of different behaviors over and over and keeping the ones that worked.
Ikea assembly is the killer app
Let’s say you were given three bowls, with red and green balls in the center one. Then you’re given this on a sheet of paper:
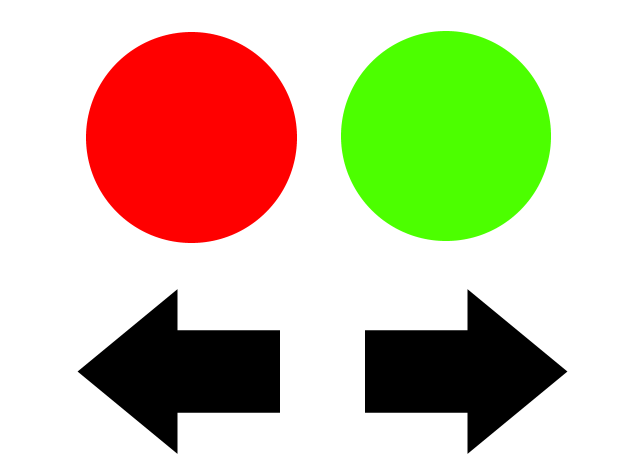
As a human with a brain, you take this paper for instructions, and you understand that the green and red circles represent balls of those colors, and that red ones need to go to the left, while green ones go to the right.
This is one of those things where humans apply vast amounts of knowledge and intuitive understanding without even realizing it. How did you choose to decide the circles represent the balls? Because of the shape? Then why don’t the arrows refer to “real” arrows? How do you know how far to go to the right or left? How do you know the paper even refers to these items at all? All questions you would resolve in a fraction of a second, and any of which might stump a robot.
Researchers have taken some baby steps towards being able to connect abstract representations like the above with the real world, a task that involves a significant amount of what amounts to a sort of machine creativity or imagination.

Making the connection between a green dot on a white background in a diagram and a greenish roundish thing on a black background in the real world isn’t obvious, but the “visual cognitive computer” created by Miguel Lázaro-Gredilla and his colleagues at Vicarious AI seems to be doing pretty well at it.
It’s still very primitive, of course, but in theory it’s the same toolset that one uses to, for example, assemble a piece of Ikea furniture: look at an abstract representation, connect it to real-world objects, then manipulate those objects according to the instructions. We’re years away from that, but it wasn’t long ago that we were years away from a robot getting up from a fall or deciding a suction cup or pincer would work better to pick something up.
The papers and videos demonstrating all the concepts above should be available at the Science Robotics site.
Source: Tech Crunch